Batch Normalization在联邦学习中的应用 |
您所在的位置:网站首页 › via local › Batch Normalization在联邦学习中的应用 |
Batch Normalization在联邦学习中的应用
|
回想一下联邦学习(FL)中的FedAvg,这个算法是将每个参与方的模型的所有参数进行加权平均聚合,包括Batch Normalization(BN)的参数。 再回顾一下BN。式中µ和
σ
2
σ^2
σ2为BN统计量,是通过每个channel的空间和批次维度计算而得的running mean和running variances。γ和β为实现"变换重构"的超参数。ε用于预防分母为零。 |
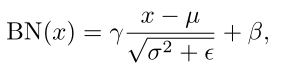 我们知道FL的一个重要意义就在于保护参与方的数据隐私,而BN层的统计参数µ和
σ
2
σ^2
σ2实际上在一定程度上隐含着本地数据的统计信息,所以把这些参数用于聚合会对数据隐私造成一定威胁,并且影响全局模型的收敛性和精度。 对于这个问题,目前我看到的主要有两种方法:
我们知道FL的一个重要意义就在于保护参与方的数据隐私,而BN层的统计参数µ和
σ
2
σ^2
σ2实际上在一定程度上隐含着本地数据的统计信息,所以把这些参数用于聚合会对数据隐私造成一定威胁,并且影响全局模型的收敛性和精度。 对于这个问题,目前我看到的主要有两种方法:【本文地址】